Spark에서의 Data Skew 문제
(재미삼아 Jekyll로 페이지를 하나 만들어봤는데… 은근히 빡세다 -_-; 호스팅 블로그들은 글 쓰는 건 편하긴 하지만… 뭔가 답답한 것들이 많아서 그냥 이 쪽으로 전향할까 싶다. 대신 글쓰긴 좀 불편하긴 하네… 리눅스 쓰는 기분?)
이틀 정도 data skew 문제로 홍역(?)을 치르고서 삽질기를 남긴다.
Data skew 라면 결국 데이터가 한쪽으로 쏠린다는 얘긴데 분산 환경의 Software라면 겪을 수 밖에 없는 문제가 아닐까 싶다.
기본적으로는 node간 데이터 처리량이 달라지면서 다수의 node들이 소수의 node의 작업이 끝나기를 기다리는 양상이 된다.
문제
일단 내가 겪은 문제는 Spark SQL에서 발생하였으며 문제가 발생한 조건은 간략화하면 아래와 비슷하다.
WHERE
w.keystr = r.keystr
AND
CASE WHEN r.is_regex
THEN w.value rlike r.pattern
ELSE w.value = r.pattern
END주요 Column 들은 모두 string 타입이며 is_regex만 bool 타입이다. pattern 컬럼은 is_regex이가 true이면 정규표현식 문자열을 갖고 있으며 false 일경우 일반 문자열이다. 그러므로 is_regex의 여부에 따라 rlike 비교를 할지, exact match를 할지가 결정된다. 앞뒤로 다른 작업들이 있긴 하지만 100M 정도의 정상적인 데이터에 대해 로컬(Macbook Pro)에서 20여초에 끝나는 작업이었다.
문제는 150M 정도의 구성이 좀 다른 데이터였는데 처음에는 OOM이 발생했으나 데이터 클린징과 관계된 문제라고 생각해서 일부 가공 후 새로 돌렸더니 거의 10분 넘게 걸렸다. 누가 봐도 이상하므로 문제 파악에 나섰다. 그리고 확인한 것은 위에 인용된 코드 부분의 stage가 실행되면서 200개 중 하나의 task가 10분 가까이 돌고 있는 것이었다.
현상으로 얘기한다면 로그가 찍히다가 딱 아래 상태에서 멈춰있었다(보다시피 199개까지는 task가 모두 ms 단위에서 완료된다).
16/10/08 18:09:34 INFO scheduler.TaskSetManager: Finished task 197.0 in stage 5.0 (TID 428) in 130 ms on 192.168.0.52 (196/200)
16/10/08 18:09:34 INFO scheduler.TaskSetManager: Finished task 198.0 in stage 5.0 (TID 429) in 35 ms on 192.168.0.52 (197/200)
16/10/08 18:09:34 INFO scheduler.TaskSetManager: Finished task 199.0 in stage 5.0 (TID 430) in 35 ms on 192.168.0.52 (198/200)
16/10/08 18:09:34 INFO scheduler.TaskSetManager: Finished task 151.0 in stage 5.0 (TID 382) in 595 ms on 192.168.0.52 (199/200)
이는 job의 web ui에서도 확인 가능하다.
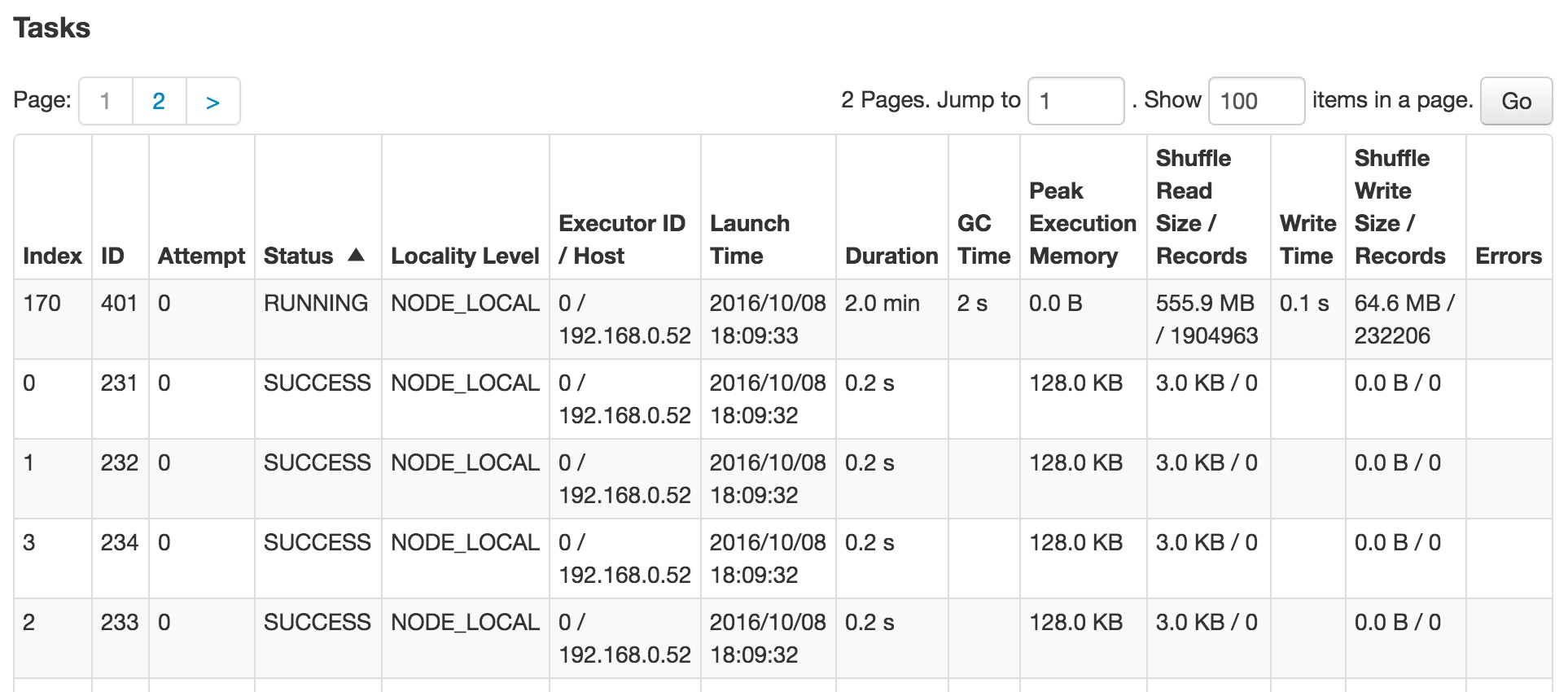
Read / Write 수치만 봐도 이미 정상적이지 않음을 알 수 있다. 좀 더 상황을 확실히 파악하기 위해 SQL plan을 출력해보자. 쿼리 실행 계획은 애플리케이션 안에서 action을 실행하지 않고 아래처럼 dataframe의 explain을 호출하면 실제 operation은 이루어지지 않고 실행 계획만 출력하고 끝나게 되므로 디버깅 목적으로 유용하다.
df.explain(false)인자는 전체 계획을 출력할 지의 여부인데 true로 주면 Parsed Logical Plan, Analyzed Logical Plan, Optimized Logical Plan, Physical Plan을 모두 출력하며 false로 주면 Physical Plan만을 출력한다. 실제로 어떤 방식으로 실행되는지만 파악하면 되므로 기본적으로는 false로 충분하다.
Physical Plan 출력 결과는 간략화 하면 아래와 같다.
Filter CASE WHEN …
+- SortMergeJoin [keystr#6], [keystr#69]
:- Sort [keystr#6 ASC], false, 0
: +- …
+- Sort [keystr#69 ASC], false, 0
+- …
보면 keystr 컬럼으로 먼저 두 테이블에 대해 정렬하고 SortMergeJoin을 수행한 후 CASE WHEN 조건으로 필터링 하는 것을 알 수 있다. 위에서 데이터가 구성이 좀 다르다고 얘기했는데 정상적인 경우 keystr 컬럼이 다양하게 분포가 되어 있지만 이 경우는 keystr 컬럼이 거의(95% 이상?) empty string이었다. 그러므로 keystr 컬럼에 대해 정렬하고 task를 나누는 상황에서 empty string인 레코드들은 모조리 하나의 task에 들어가 버리는 상황이 발생한 것이다.
상황 분석
물론 일차적인 원인은 스파크 SQL의 최적화에 있다. 일반적인 상황에서는 equal 조건으로 먼저 join 하여 레코드 개수를 줄이고 복잡한 case when 을 수행하는 것이 성능에는 도움될 수 있다. 하지만 이 경우는 예외적인 상황이고 RDBMS도 아닌 스파크 SQL이 테이블의 데이터 분포나 통계까지 파악하여 실행 계획을 수립해 주리라 보기에는 문제가 있다.
제일 이상적인 방법은 물론 CASE WHEN을 equal 조건보다 먼저 수행하는 것이다. 이를 위해 일차적으로 조인 순서를 바꿔보았지만 아쉽게도 optimizer가 똑똑한(?) 탓인지 실행 계획이 변하지는 않았다.
두번째로 시도해 본 방법은 가독성 저하를 감수하고 case when 안에 equal 조건을 중복으로 넣는 것이었다.
WHERE
CASE WHEN r.is_regex
THEN w.keystr = r.keystr AND w.value rlike r.pattern
ELSE w.keystr = r.keystr AND w.value = r.pattern
END 하지만 이는 다른 문제가 생겼는데 SortMergeJoin의 경우에는 원본 데이터를 정렬만 한 후 조건에 맞는 것만 조인 결과로 만들기 때문에 데이터량을 크게 줄일 수 있지만 위와 같은 식으로 SQL을 적용하자 일단 w와 r에 대한 cartesian product 부터 돌리고 난 뒤 case when 조건을 수행하는 실행 계획을 잡는 것이었다. 이는 이미 cartesian product 단계에서 엄청난 작업량을 요구하기 때문에 빈대 잡으려고 초가삼간 태우는 격이었다. 그래서 이것도 포기…
참고로 keystr와 value라고 컬럼 이름을 임의로 표시하긴 했지만 둘은 일종의 복합키이기 때문에 쿼리 자체를 분리하는 것은 곤란했다.
그리고 보통 OOM 등의 경우에 스파크 관련 글들에서 추천하는 방법들은 executor heap size를 늘리라거나 메모리 분배 설정을 바꾸라는 내용이 많은데 문제 상황 자체가 비정상적인 경우가
많기 때문에 저런 ‘정상적인’ 해결책은 도움이 안 되는 경우가 많았다.
그 외에 파티셔닝 방법을 바꾸라는 글들도 있지만 SQL의 경우는 최적화 하면서 파티셔닝을 알아서 다 바꾸므로 역시 도움은 되지 않았다.
해결
잡설이 길었지만 이런 경우에 쓰는 해법은 편법이나마 비교적 간단한 방법이 있다. 아래 링크를 참고해 보면 도움이 될 것이다.
Fighting the skew in Spark. 제목부터 도발적이다. 링크의 절차를 요약하면 아래와 같다.
- 두 개의 RDD가 있으며 큰 쪽의 data가 편향된 상태라고 가정.
- 새로운 dummy 컬럼을 하나 만들고 작은 쪽 RDD의 데이터를 원하는 횟수만큼 복제하면서 dummy 값을 다르게 한다.
- 큰 쪽 RDD에도 dummy 컬럼을 만들고 위에서 복제한 횟수 범위만큼 random하게 값을 넣는다.
- 조인하면서 dummy 컬럼에 대한 equal 조건을 먼저 주면 random하게 준 값에 따라 자연스럽게 split 된다.
나도 안다. 말로 쓰니까 복잡한 거. 예제 데이터로 설명하겠다.
편향된 데이터의 컬럼은 아래와 같다고 하자.
skewed
-—–
1
2
3
4
0
0
0
…(0이 1억개쯤… 여튼 많다고 가정)
그리고 아래는 작은 쪽 데이터
keys
-—
0
1
2
3
그럼 여기서 작은 쪽 데이터에 dummy 컬럼을 추가하고 복제한다. 20배로 복제한다고 가정하자. 그럼 작은 쪽은 아래와 같이 바뀐다.
keys, dummy
-———-
0, 1
1, 1
2, 1
3, 1
0, 2
1, 2
2, 2
3, 2
0, 3
…
2, 20
3, 20
그리고 skewed data에는 random값으로 dummy를 추가한다.
skewed, dummy
-—–
1, 18
2, 2
3, 8
4, 11
0, 15
0, 12
0, 5
…
그리고 dummy 값에 대한 조건을 추가하고 join을 시도한 후 dummy 컬럼은 날리면 끝이다. 이게 뭔가 하고 생각할 수도 있겠지만 이렇게 하면 dummy에 따라(hash든 range든) task를 나눠서 node들에 나눠지게 되므로 특정값이 많을 경우에 특정 node로 작업이 몰리는 것을 막아줄 수 있다.
이 방식은 작은 쪽 데이터를 dummy 값 개수만큼 복제를 하게 되므로 데이터가 웬만큼 작아야 적용이 가능한 방법이다. 복제를 하게 됨으로써 동일 데이터가 조인을 위해 여러 노드에 분산될수 있도록 해준다. 다시 말하면 dummy 값이 일종의 파티션 id라고 볼 수도 있다.
링크는 rdd에 대한 내용을 다루고 있으나 스파크 SQL에서는 직접 적용하기 힘들므로 withColumn과 udf를 써서 같은 방식으로 적용하는게 낫다.
(rdd로 바꿔서 해도 안될 건 없지만 다시 dataframe으로 만드는게 약간 귀찮다)
작은 테이블 쪽에는
val dummySeq = sqlContext.createDataFrame(
sc.parallelize((1 to 20).map(i => Row(i))),
StructType(Array(StructField("partid", IntegerType))))위와 같은 식으로 dummy dataframe을 생성한 후 join을 해주면 cartesian product가 일어나서 바로 복제된 테이블이 만들어지며, skewed table 쪽은
val randomUDF = udf(() => {
new Random().nextInt(20) + 1
})이런 식의 udf를 만들어서 새 컬럼을 추가해 준다.
여기까지 되었으면 SQL 문의 where 조건에 양쪽 dummy에 대한 equal join 조건을 걸어 주면 데이터가 적절히 분산되어서 처리된다. 주의할 점은 데이터 복제 계수를 해당 stage의 task 개수에 맞춰 주는 것이 좋다. 그렇지 않으면 정도가 낮지만 마찬가지로 skew가 일어날 수 있다. 문제는 Spark SQL은 dynamic planning을 하므로 task가 몇 개가 될 지는 미리 알기가 힘들기 때문에 테스트를 돌려 보면서 결정하는 편이 나을 것이다.